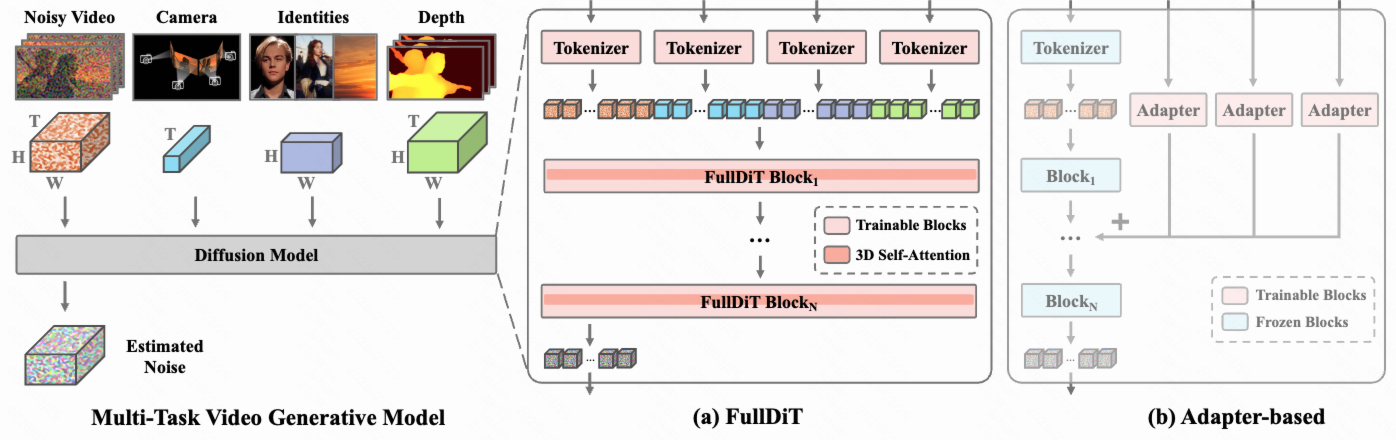
Current video generative foundation models primarily focus on text-to-video tasks, providing limited control for fine-grained video content creation. Although adapter-based approaches (e.g., ControlNet) enable additional controls with minimal fine-tuning, they encounter challenges when integrating multiple conditions, including: branch conflicts between independently trained adapters, parameter redundancy leading to increased computational cost, and suboptimal performance compared to full fine-tuning. To address these challenges, we introduce FullDiT, a unified foundation model for video generation that seamlessly integrates multiple conditions via unified full-attention mechanisms. By fusing multi-task conditions into a unified sequence representation and leveraging the long-context learning ability of full self-attention to capture condition dynamics, FullDiT reduces parameter overhead, avoids conditions conflict, and shows scalability and emergent ability. We further introduce FullBench for multi-task video generation evaluation. Experiments demonstrate that FullDiT achieves state-of-the-art results, highlighting the efficacy of full-attention in complex multi-task video generation.
Overview of FullDiT architecture and comparison with adapter-based models. We present the diffusion process of the multi-task video generative model on the left. For research purposes, this paper shows input conditions consisting of temporal-only cameras, spatial-only identities, and temporal-spatial depth video. Additional conditions can be incorporated into this model architecture for broader applications. Shown in (a), FullDiT unifies various inputs with procedures: (1) patchify and tokenize the input condition to a unified sequence representation, (2) concat all sequences together to a longer one, and (3) learn condition dynamics with full self-attention. By comparison, earlier adapter-based approaches (shown in (b)) use distinct adapter designs that operate independently to process various inputs. The subscript of each block signifies its layer index.
Advantages:
(1) Long-context learning ability ⮕ Better performance and controllability
(2) Unified Representation ⮕ Scalable extension to additional modalities or conditions without major architectural modifications
(3) Strong scalability ⮕ Higher training data utilization rate
(4) Emergent capabilities ⮕ Generalizing to previously unseen combinations of conditions
Quantitative comparison of single task video generation. We compare FullDiT with MotionCtrl[1], CameraCtrl [2], and CamI2V [3] on camera-to-video generation. For identity-to-video, due to a lack of open-source multiple identities video generation method, we compare with the internal 1B model: ConceptMaster [4]. We compare FullDiT with Ctrl-Adapter [5] and ControlVideo [6] for depth-to-video. We follow the default setting of each model for evaluation. Since most of previous methods can generate only 16 frames of video, we uniformly sample 16 frames from methods that generate more than 16 frames for comparison.
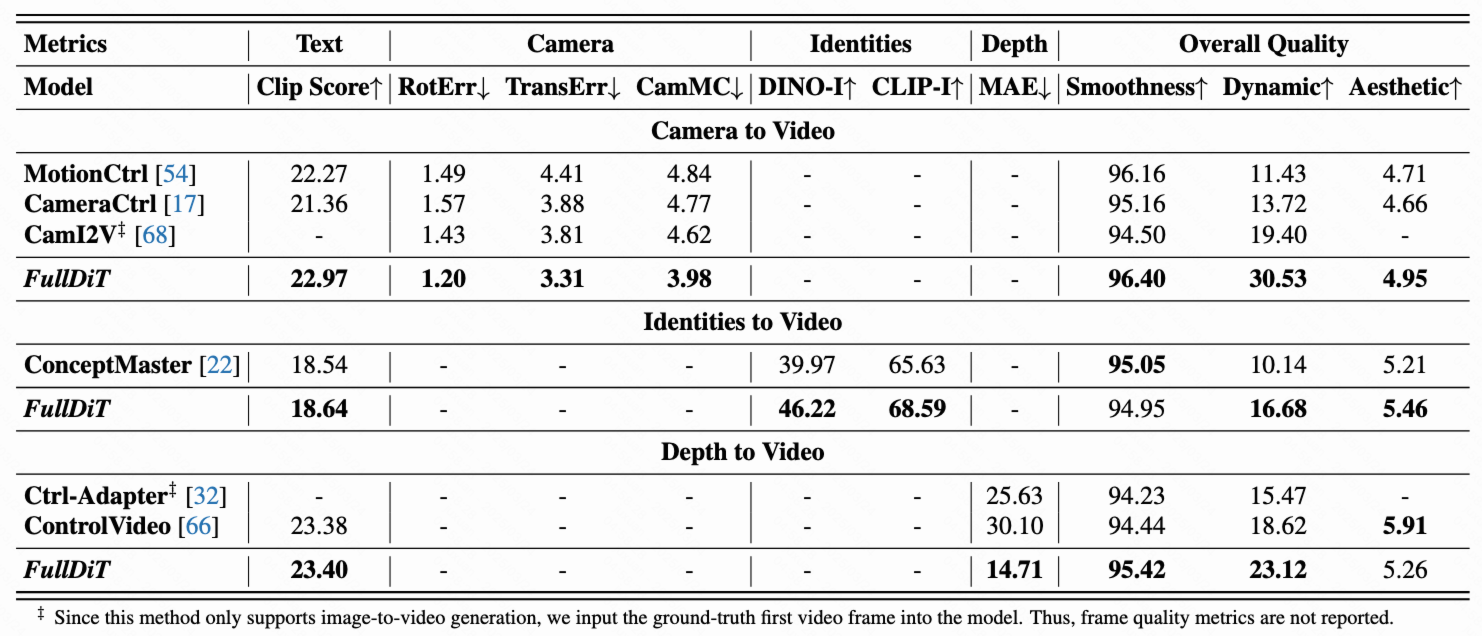
Qualitative comparison of FullDiT and previous single control video generation methods. We present identity-to-video results compared with ConceptMaster[4], depth-to-video results compared with Ctrl-Adapter[5] and ControlVideo[6], and camera-to-video results compared with MotionCtrl[1], CamI2V[3], and CameraCtrl[2]. Results denoted with * are image-to-video methods.

|

|

|

|

|

|

|

|

|

|
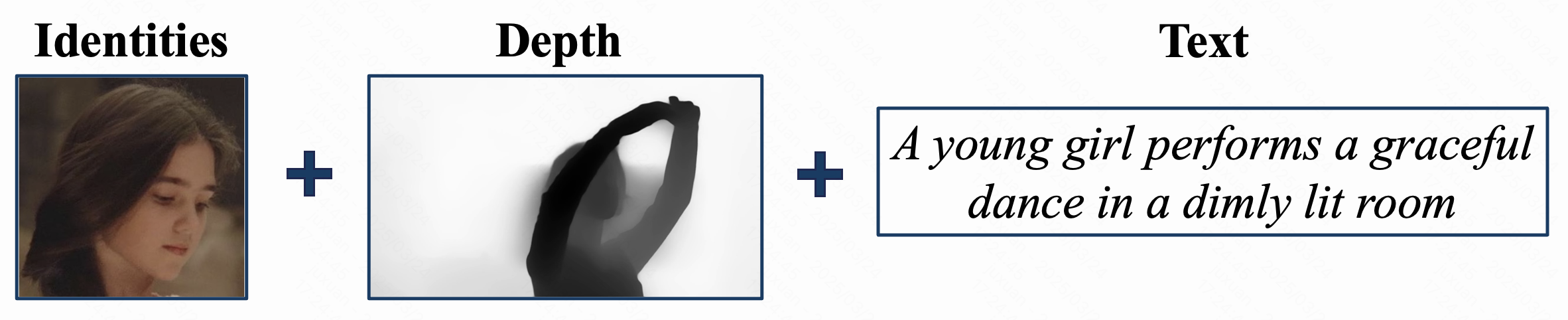
|

|

|
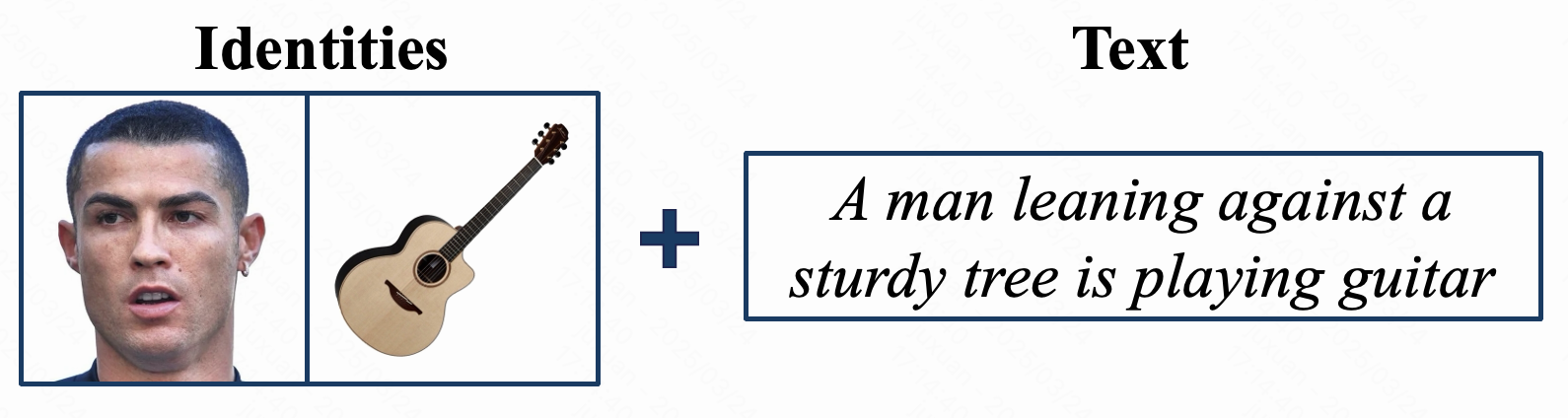
|
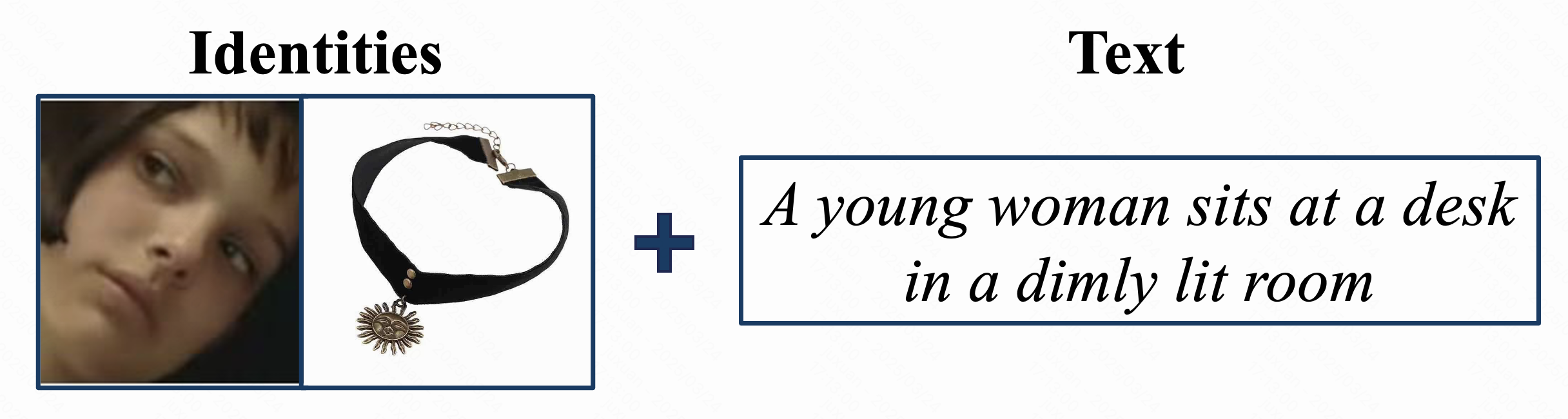
|
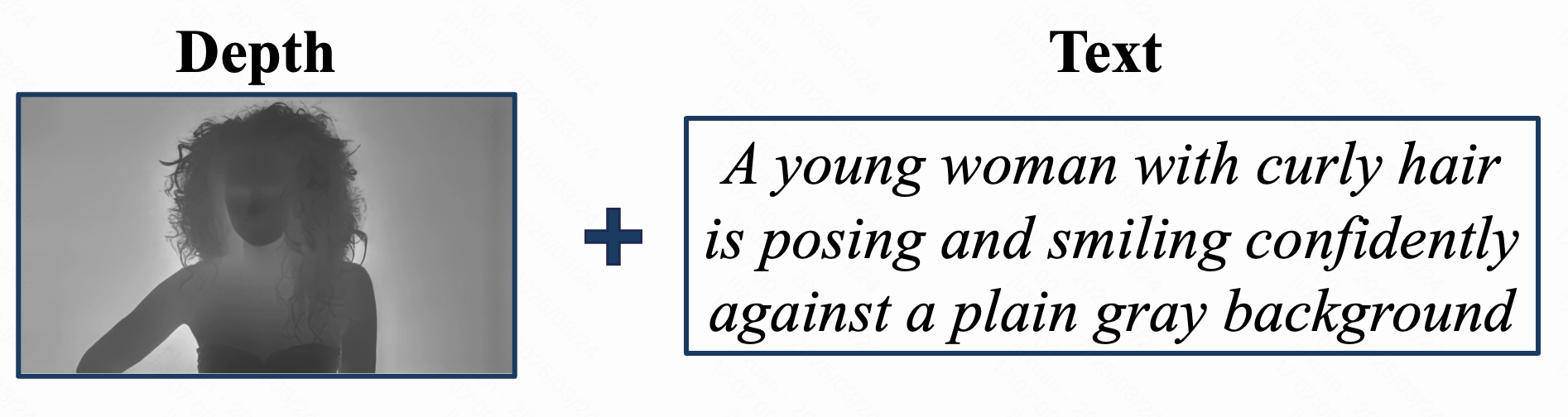
|
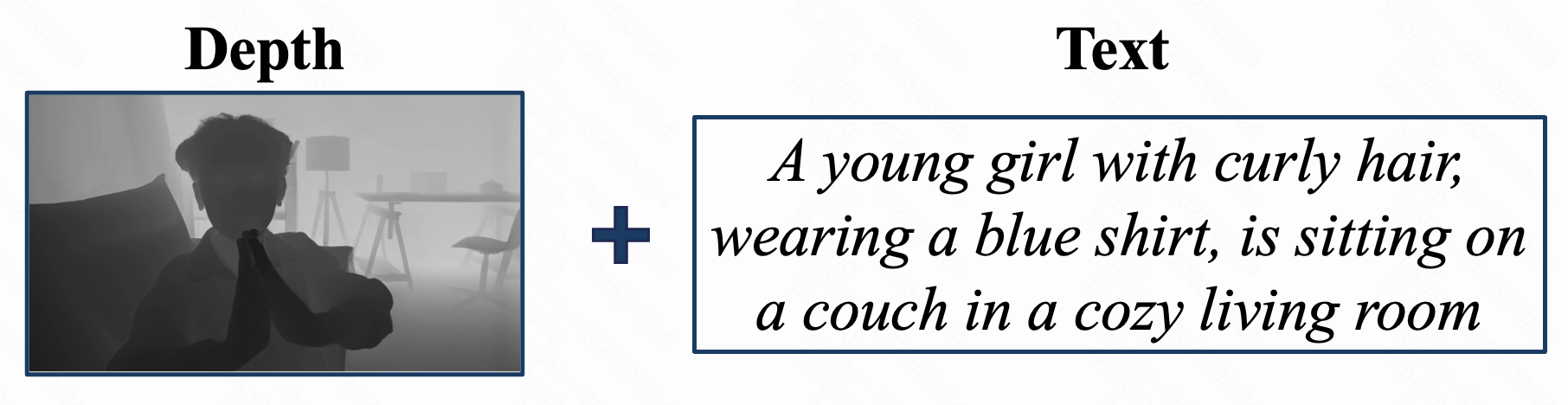
|
|

|

|

|
